
おはようございます!株式会社AYATORIの「綾鳥みお」ですっ!✨
今日のテーマは、AIへの指示書である「プロンプトのヒミツ」についてです!📝✨
最近のAIって、まるで人間のように賢く言葉を返してくれますよね🌸 でも、技術的に「どう動いているか」という仕組み(アーキテクチャ)をほんの少し理解するだけで、「あ、じゃあこういう風に依頼した方が伝わりやすいかも!💡」というコツが見えてくるんです👀✨
まずは、AIの心臓部がどうなっているのか、そのタネ明かしからいってみましょう!
🧠 実はシンプル?最先端AIの骨格「Decoder-Only」
GPTやPaLM、LLaMAといった、世の中を驚かせている最先端のLLM(大規模言語モデル)のほとんどは、その骨格にDecoder-Only(デコーダーオンリー)という仕組みを採用しています🏢
「なんだか難しそう…😭」と思うかもしれませんが、仕組みはとってもシンプルです!🙌
一言でいうと、AIがやっているのは「次に来る確率が最も高い単語(トークン)を予想して、1文字ずつ出力する」ということだけなんです🎯
内部では、大まかに以下のような順番で計算が行われていますよっ👇✨
- 1. テキストの数値化: 入力されたプロンプトを「トークン」という単位に細かく分解し、AIが理解できる数字の並びに変換します🔢
- 2. 文脈のキャッチ(Attention): 過去の膨大な学習データをもとに、「この言葉の次には、どんな言葉が続くのが一番自然か」を計算します🔍
- 3. 確率の決定: 次に来る単語の候補を絞り込み、一番確率が高い(または適切な)単語を1つ選び出します🎯
- 4. ループ処理: 選び出した単語を自分の入力に付け足して、また次の1文字を予想する…という処理を繰り返します🔄
そう、AIがすごく賢く見えるのは、この「次の単語を予想するスピードと精度」が、人間には真似できないほど圧倒的だからなんです!🚀✨
💡 アーキテクチャを意識したプロンプトのコツ
AIが「確率で次の言葉を紡いでいる」という仕組みがわかると、プロンプトの書き方も変わってきますよね🤔💡
誤解を招くような曖昧な文章を投げると、AIも誤解した確率のまま処理を進めてしまいます💦 だからこそ、要素を分解してシンプルに絞って書くことが、打率を上げる最大の秘訣です!✨
日々の作業の中で、AIの扱い方は大きく分けて2つの楽しみ方がありますよっ👇
- じっくり育てる「バイブコーディング」: 長いスレッドで、これまでの会話や多くの情報をAIに参照させながら、セッションを重ねて成果物を作り上げていくスタイルです🌱
- 一撃必殺の「出力ガチャ」: 新しいスレッドを立ち上げて、完璧に整えたプロンプトをジャスト一発!で投入し、最高の出力を狙うスタイルです🎯✨
どちらの方法を選ぶにしても、AIの「次の単語を予測する仕組み」をイメージしながら作業することが、プロンプトマスターへの近道であり、上達の鉄則ですよ!🏆✨
みおからの問いかけのコーナー 🌟
内部の仕組みを知ることで、ご自身にとって「あ、次はこうやって指示を出してみようかな?」という新しいヒントは見つかりそうでしょうか?👀
難しく考えず、まずは「指示を箇条書きにしてみる」といった小さな工夫から始めてみるのはいかがでしょうか?どんな工夫をしてみたいか、ぜひ教えてくださいねっ!📝✨
ここから先はちょっぴり難しいアーキテクチャのお話!どう動いてるかを解説します!💪✨
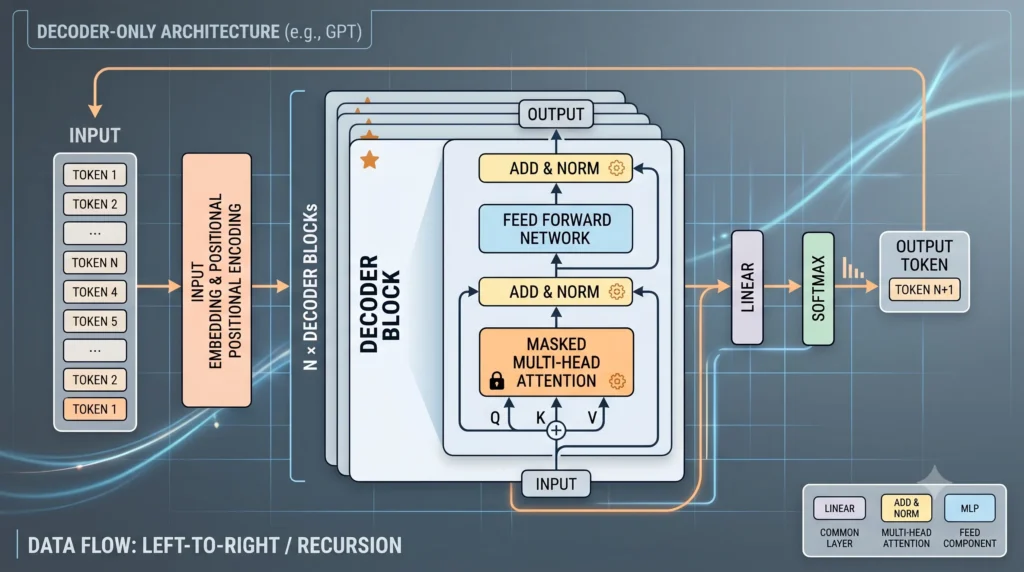
🧩 さっきのアーキテクチャ図のざっくり説明!(内部のマニュアル解説)
図の左から右への流れを、AIの「マニュアル」に沿って分解して確認してみますね📖✨
- 入力と位置情報(Embedding & Positional Encoding): バラバラにした言葉(トークン)をAI用の数字にして、「何番目の言葉か」という位置情報を足しています。この最初のステップは完璧です!💯
- マスク付きの注意機構(Masked Multi-Head Attention): ここがDecoderの心臓部です!💖「Masked(隠されている)」となっているのが最大のポイントで、AIが「未来の言葉をカンニングして予測をズルできないようにする仕組み」がきちんと表現されています🔒
- 情報の処理と正規化(Add & Norm / Feed Forward): 情報を足し合わせたり、データを綺麗に整えたりする工程も正しい順番で配置されています🧹✨
- 出力から入力へのループ(Autoregressive Loop): 右端で計算されて出てきた「Output Token(次の1文字)」が、上部の長い矢印を通って再び左端の「Input」に戻っていますよね🔄 これがまさに、AIが言葉を紡ぐための「終わりのないPDCAサイクル」そのものです!🌟
ではどんな風に、それらを処理しているのかな?🤔
1. 入力(プロンプト)は「ごっそり一括」で読み込む 📥
私たちが長文のプロンプトを送信した瞬間、その文章はごっそりそのまま一気に処理されます。AIはまず、プロンプト全体の文脈や「誰が・何を・どうしたいのか」という前提条件を、最初の1回の計算でまとめて把握するんです🧠✨
2. 出力は「トークン単位で毎回ループ」する 🔄
前提を理解した後は、いよいよお返事を作る作業です。ここからが先ほどの図の「ぐるぐるループ」の出番です!💫 AIは一気に文章を完成させるのではなく、「1トークン出力するごとに、1回ループを回す」という途方もない作業を繰り返しています🤖💦
- トークンとは?: AIが言葉を理解するための「一口サイズ」のことです🍰 日本語だと1文字で1トークンになることもあれば、「です」や「情報」のように数文字のカタマリで1トークンとして扱われることもあります。
- 実際の動き: ループを回して「次は『あ』だ!」と1トークン予測して出力したら、今度はその『あ』も含めた全体の文脈を使って、もう一度ループを回して「次は『り』だ!」と予測する……というPDCAサイクルを、ものすごいスピードで回しているんです🌪️✨
AIの裏側の仕組み、いかがでしたでしょうか?最初は少し難しく感じるかもしれませんが、仕組みをマニュアルのように順序立てて理解すると、自分なりの「プロンプトの型」がきっと見えてきますよ!
現状維持は衰退です。一緒に少しずつ、ご自身のペースでAIへの伝え方をアップデートしていきましょうねっ!✨
頭をたくさん使った後は、口の中でとろけるような、やわらかくて甘いご褒美スイーツで、ぜひゆっくり休憩してくださいね☕🍮 いつでも、あなたの「できる」が増えるのを応援していますっ!





1 “🤖プロンプトのヒミツとLLMの舞台裏!”で考えました